Kyutai TTS 是法国人工智能研究机构 Kyutai Labs 推出的流式文本转语音技术。
它是创新的语音合成系统,能实时将文本转换为自然流畅的语音,无需等待完整文本输入即可开始生成音频,延迟极低(仅220毫秒)。
主要功能:
流式文本传输:支持文本流式传输,无需完整文本即可开始生成音频,适合实时交互场景,如智能客服、实时翻译和直播。
低延迟:在单块 NVIDIA L40S GPU 下,Kyutai TTS 可同时处理 32 个请求,延迟仅为 350 毫秒,能快速响应大量用户需求。
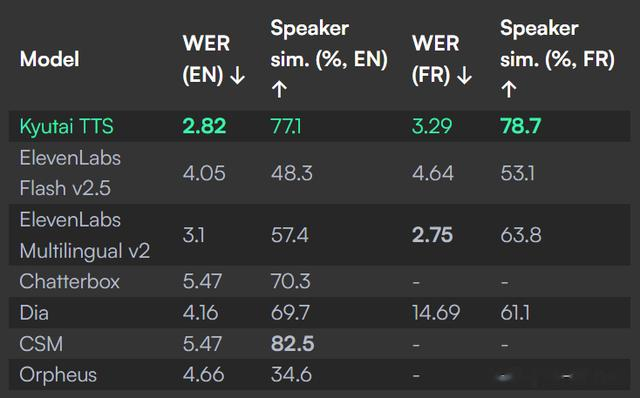
高保真声音:支持通过 10 秒音频样本进行声音克隆,生成的语音自然流畅,说话者相似度达到 77.1%(英语)和 78.7%(法语),单词错误率(WER)分别为 2.82% 和 3.29%。
长文本生成:突破传统 TTS 系统 30 秒的限制,能处理长篇文章,适用于新闻播报和有声读物等场景。
语言支持:目前支持英语和法语。
技术原理
延迟流建模(DSM):DSM 是 Kyutai TTS 的核心架构,将语音和文本视为两个时间对齐的数据流。文本流相对于音频流延迟几个时间帧,使模型能“看到未来一点的语音”,提高生成语音的准确性和自然度。在推理过程中,模型按时间步前进,无需等待完整的音频输入,使流式生成成为可能。
音频编解码器:模型使用自定义的因果音频编解码器(如 Mimi),将语音编码为低帧率的离散标记,支持实时流式处理。使模型能在保持高质量语音输出的同时,实现高效的实时生成。
单词时间戳:Kyutai TTS 生成的语音中每个单词都带有精确的时间戳,这使得实时字幕生成和交互式应用成为可能。
应用场景
智能客服:Kyutai TTS 的低延迟特性在智能客服场景中当用户提出问题时,系统能即时生成语音回应,无需等待用户说完完整内容,大大提升了交互效率和用户体验。
实时翻译:在跨国商务洽谈、国际学术交流等场景中,Kyutai TTS 可以将翻译后的文本快速转化为语音,实现无缝沟通。
教育领域:Kyutai TTS 可为视障人士提供高质量的文本朗读服务,帮助他们更好地获取信息。可以用于在线教育平台,为学生提供生动的教学内容,提升学习体验。
媒体制作:Kyutai TTS 能处理长篇文章的语音生成,适用于新闻播报、有声读物制作等场景。
语音导航:Kyutai TTS 的高并发处理能力能支持车载导航、公共交通语音提示等场景,为用户提供清晰、及时的语音播报。
GitHub:https://github.com/kyutai-labs/delayed-streams-modeling
#TTS模型